Mai sottovalutare un database.
Partito da una semplice tavoletta di argilla, è diventato protagonista della raccolta e della gestione dei dati dell’azienda.
E sarà decisivo per un buon uso dell’AI.

Immaginate un responsabile acquisti di una media azienda manifatturiera lombarda. Ogni giorno deve gestire centinaia di fornitori, migliaia di codici articolo, prezzi che cambiano, scadenze da rispettare. Quaranta anni fa avrebbe avuto schedari metallici, registri cartacei, appunti sparsi. Oggi apre il suo gestionale e in pochi click ha tutto: storico ordini, confronto prezzi, alert automatici.Questa rivoluzione silenziosa ha un nome: database. Ma da dove viene questa tecnologia che oggi diamo per scontata?
Le origini: quando l'uomo iniziò a organizzare i dati in tabelle
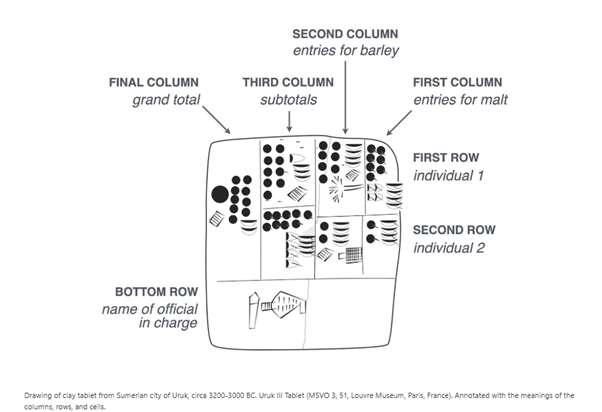
La storia dei database inizia molto prima dei computer. L'istinto umano di organizzare informazioni in righe e colonne è antico quanto la necessità di dare senso al mondo che ci circonda. Già nell'antica Mesopotamia, i registri commerciali venivano incisi su tavolette d'argilla seguendo una struttura tabulare. Le tavolette di Uruk già sommano orzo e malto per destinatario; è una logica di record e campi che ci è immediata ancora oggi. La storia delle tabelle mostra perché questo formato è così resiliente: rende confrontabili entità diverse e fa emergere pattern al primo sguardo. Una tabella ben progettata comunica immediatamente relazioni complesse: ogni riga è un'entità (un cliente, un prodotto, una transazione), ogni colonna è un attributo, ogni cella è un punto dati. Questa struttura mentale, apparentemente semplice, è alla base di tutto ciò che è venuto dopo. Ma è nel corso del XX secolo che la tabella diventa lo strumento principe per rappresentare dati. Quando i primi computer sono entrati nelle aziende negli anni '60, il problema era chiaro: come trasferire questa capacità organizzativa dalla carta al silicio? Come permettere a migliaia di utenti di accedere, modificare e interrogare gli stessi dati senza caos? La risposta fu rivoluzionaria. L'era dei database relazionali: SQL e la democratizzazione dei dati
Nel 1970, Edgar F. Codd, un ricercatore IBM, pubblicò un articolo che avrebbe cambiato per sempre il modo in cui gestiamo le informazioni: "A Relational Model of Data for Large Shared Data Banks". L'intuizione era elegante nella sua semplicità: organizzare i dati in tabelle correlate tra loro attraverso chiavi comuni, e fornire un linguaggio standardizzato per interrogarli. Nasceva SQL (Structured Query Language). Per comprendere l'impatto di questa innovazione, torniamo al nostro responsabile acquisti. Prima dei database relazionali, ogni applicazione aveva il proprio modo di salvare e recuperare dati, spesso incompatibile con le altre. Con SQL, improvvisamente era possibile fare domande complesse ai propri dati con semplici comandi in linguaggio quasi naturale: "Mostrami tutti i fornitori che mi hanno consegnato in ritardo negli ultimi sei mesi" diventa una query di poche righe. Cinquant'anni dopo quella pubblicazione, SQL è ancora il linguaggio più utilizzato per gestire dati aziendali. Oracle, Microsoft SQL Server, MySQL, PostgreSQL: questi sistemi alimentano i gestionali, i siti di e-commerce, i sistemi bancari di tutto il mondo. Il modello relazionale ha vinto perché garantisce coerenza, integrità dei dati e, soprattutto, prevedibilità. In un database relazionale ben progettato, ogni dato ha il suo posto, le relazioni sono esplicite, le regole sono chiare. Per le aziende, questo ha significato poter costruire sistemi informativi affidabili, scalabili e manutenibili nel tempo. Il CFO può essere sicuro che il bilancio sia calcolato su dati coerenti, il direttore commerciale può analizzare le vendite sapendo che ogni transazione è registrata correttamente, il responsabile logistica può coordinare magazzini in paesi diversi fidandosi dell'accuratezza delle giacenze. L'evoluzione: NOSQL e l'adattamento alla nuova complessità
 Ma il mondo cambia, e con esso cambiano le esigenze.Con l'avvento di Internet, dei social media, dell'IoT (Internet of Things), le aziende si sono trovate a gestire volumi di dati impensabili solo vent'anni fa: siamo entrati nell’era dei Big Data.Non più solo transazioni strutturate, ma anche documenti JSON, grafi di relazioni sociali, serie temporali di sensori, immagini, video. E soprattutto, una velocità di generazione dati che rendeva difficile mantenere la rigidità del modello relazionale tradizionale.Nasce così la filosofia NoSQL (Not Only SQL), non come sostituto ma come complemento ai database relazionali.
Ma il mondo cambia, e con esso cambiano le esigenze.Con l'avvento di Internet, dei social media, dell'IoT (Internet of Things), le aziende si sono trovate a gestire volumi di dati impensabili solo vent'anni fa: siamo entrati nell’era dei Big Data.Non più solo transazioni strutturate, ma anche documenti JSON, grafi di relazioni sociali, serie temporali di sensori, immagini, video. E soprattutto, una velocità di generazione dati che rendeva difficile mantenere la rigidità del modello relazionale tradizionale.Nasce così la filosofia NoSQL (Not Only SQL), non come sostituto ma come complemento ai database relazionali.
- I database documentali come MongoDB permettono di salvare dati con struttura flessibile, ideali per applicazioni web moderne.
- I database a grafo come Neo4j eccellono nel rappresentare reti di relazioni, perfetti per sistemi di raccomandazione o analisi di frodi.
- I database time-series sono ottimizzati per dati che arrivano continuamente da sensori e dispositivi IoT.
Per monitorare l'evoluzione di questo ecosistema, DB-Engines offre un ranking mondiale aggiornato costantemente che mostra come i vari database si posizionano in termini di popolarità e adozione.
È uno strumento prezioso per chi deve decidere quale tecnologia adottare, perché riflette le scelte concrete di migliaia di aziende in tutto il mondo. La lezione importante per manager e professionisti è questa: non esiste più "il" database perfetto per tutti gli usi. Le aziende più mature stanno adottando architetture di persistenza poliglotta, dove dati transazionali rimangono su database relazionali, mentre dati meno strutturati o ad alta velocità vengono gestiti con soluzioni NoSQL. La chiave è scegliere lo strumento giusto per ogni specifico caso d'uso.
Il futuro: database e intelligenza artificiale
Ed eccoci all'oggi, o meglio al domani che è già qui. L'intelligenza artificiale generativa ha portato una nuova consapevolezza: i dati sono il nuovo petrolio, ma solo se sono raffinati. ChatGPT e i suoi simili hanno dimostrato cosa si può fare con quantità massive di dati ben organizzati. Ma per le aziende, la sfida non è solo adottare l'AI: è renderla efficace sui propri dati specifici. Qui torniamo al punto di partenza: l'importanza di avere dati ordinati, puliti e ben strutturati in database appropriati.Un'azienda che per anni ha trascurato la qualità dei propri dati, che ha lasciato proliferare fogli Excel sconnessi, che non ha mai normalizzato anagrafiche e classificazioni, si troverà in grave difficoltà quando vorrà sfruttare l'AI. Al contrario, chi ha investito in una solida infrastruttura dati ha un vantaggio competitivo enorme. Può addestrare modelli di machine learning sui propri dati storici per:
- prevedere la domanda;
- identificare anomalie;
- ottimizzare processi.
Può usare l'AI generativa per interrogare in linguaggio naturale decenni di report e documenti aziendali, estraendo insight che prima richiedevano settimane di analisi manuale. I database vettoriali, l'ultima frontiera, stanno diventando essenziali per gestire gli embedding utilizzati dai modelli di AI. Permettono di fare ricerche semantiche, trovando documenti non per parole chiave ma per significato. Immaginate di cercare "contratti con clausole penali onerose" e ottenere risultati anche se nei documenti non compare mai esattamente quella frase. Per il nostro responsabile acquisti del futuro, questo significa poter chiedere al sistema: "Quali fornitori potrebbero avere difficoltà finanziarie basandoti su ritardi di consegna, variazioni di prezzo e notizie di mercato?" e ottenere una risposta ponderata, basata su dati reali e aggiornati, in pochi secondi.
Qualche consiglio
Dalla prima tabella intagliata su una tavoletta di argilla all'intelligenza artificiale, il filo rosso è sempre lo stesso: il valore non sta nei dati in sé, ma nella nostra capacità di organizzarli, interrogarli, comprenderli.
I database sono evoluti da semplici archivi a ecosistemi complessi e sofisticati, ma il principio fondamentale rimane quello delle tabelle mesopotamiche: dare struttura al caos, rendere visibile l'invisibile, trasformare l'informazione in conoscenza. Per le aziende di oggi, investire in database non significa solo comprare licenze software. Significa costruire un patrimonio informativo che sarà sempre più prezioso nel tempo, significa dotarsi dell'infrastruttura necessaria per competere nell'era dell'AI, significa garantire che ogni decisione sia basata su dati solidi e affidabili. In un mondo dove tutti hanno accesso agli stessi strumenti di intelligenza artificiale, il vero vantaggio competitivo sarà la qualità dei propri dati. E tutto inizia da una scelta di un buon database.
![]()
Artser Lab è il think tank di Artser e produce idee e contenuti, analisi ed approfondimenti per chi guida le imprese.

Autore: Stefano Gatti
Head of Data & Analytics di Nexi, autore con Alberto Danese di La cultura del dato